Solving Anthropic's Original Performance Take-Home with OpenEvolve
TL;DR - Gemini 3 Pro reaches 2,160 cycles (68.4x speedup) in 15 iterations (takes about 30 mins and $3) beating "Claude Opus 4 after many hours in the test-time compute harness", but then plateaus - 30 more iterations over 2 additional hours barely improve it. The full run costs $9. Code is here.
Background: Evolutionary LLM Systems
I was recently discussing evolutionary LLM systems - you can check the recording here and the slides here. The most famous examples are AlphaEvolve by Google DeepMind and Darwin Gödel Machine by Sakana AI.
The core algorithm is very simple:
- Initialize a population with some baseline program(s)
- Loop:
- Select program / programs from the population
- Mutate via LLM (single model, ensemble, or agent)
- Evaluate performance, then keep in the population for future selection or discard
The key hypothesis is that given quantitative (though sometimes vague or ambiguous) feedback, an LLM can iteratively optimize code. This is a natural fit for any task with a measurable objective function, and Anthropic's recently released performance take-home is a perfect use case.
Solving Anthropic's Take-Home
Anthropic released their performance take-home after Claude Opus 4.5 started solving it better than most humans in 2 hours. The challenge is to optimize a kernel for a custom VLIW SIMD architecture that runs a tree-traversal hashing algorithm.
Config Decisions
The key for the OpenEvolve run to work was making the config less restrictive than OpenEvolve's defaults. The problem context is large and the generated kernels are long, so I set max tokens and LLM timeout to much higher values - LLM call in this setting takes ~3 mins on average.
max_iterations: 15
checkpoint_interval: 5
max_code_length: 1000000
random_seed: null
llm:
models:
- name: "gemini-3-pro-preview"
weight: 1.0
api_base: "https://generativelanguage.googleapis.com/v1beta/openai/"
api_key: "${GEMINI_API_KEY}"
temperature: 0.7
max_tokens: 64000
timeout: 600
...
prompt:
system_message: |
You are an expert performance engineer optimizing code for a custom VLIW SIMD architecture.
## Full Machine Definition (problem.py)
Study this carefully to understand the exact instruction semantics:
```python
{problem_py}
```
suggest_simplification_after_chars: null
concise_implementation_max_lines: null
comprehensive_implementation_min_lines: null
diff_summary_max_lines: 10000
num_top_programs: 3
num_diverse_programs: 2
I chose Gemini 3 Pro as the LLM - I feel like it's the first "step-function improvement" model from late 2025, while remaining cost-effective. The system prompt was kept minimal on
purpose, including only the original problem.py for full problem context.
Results
I ran it first for 15 iterations, which produced a best result of 2160 cycles - beating the 2164 cycles achieved by "Claude Opus 4 after many hours in the test-time compute harness."
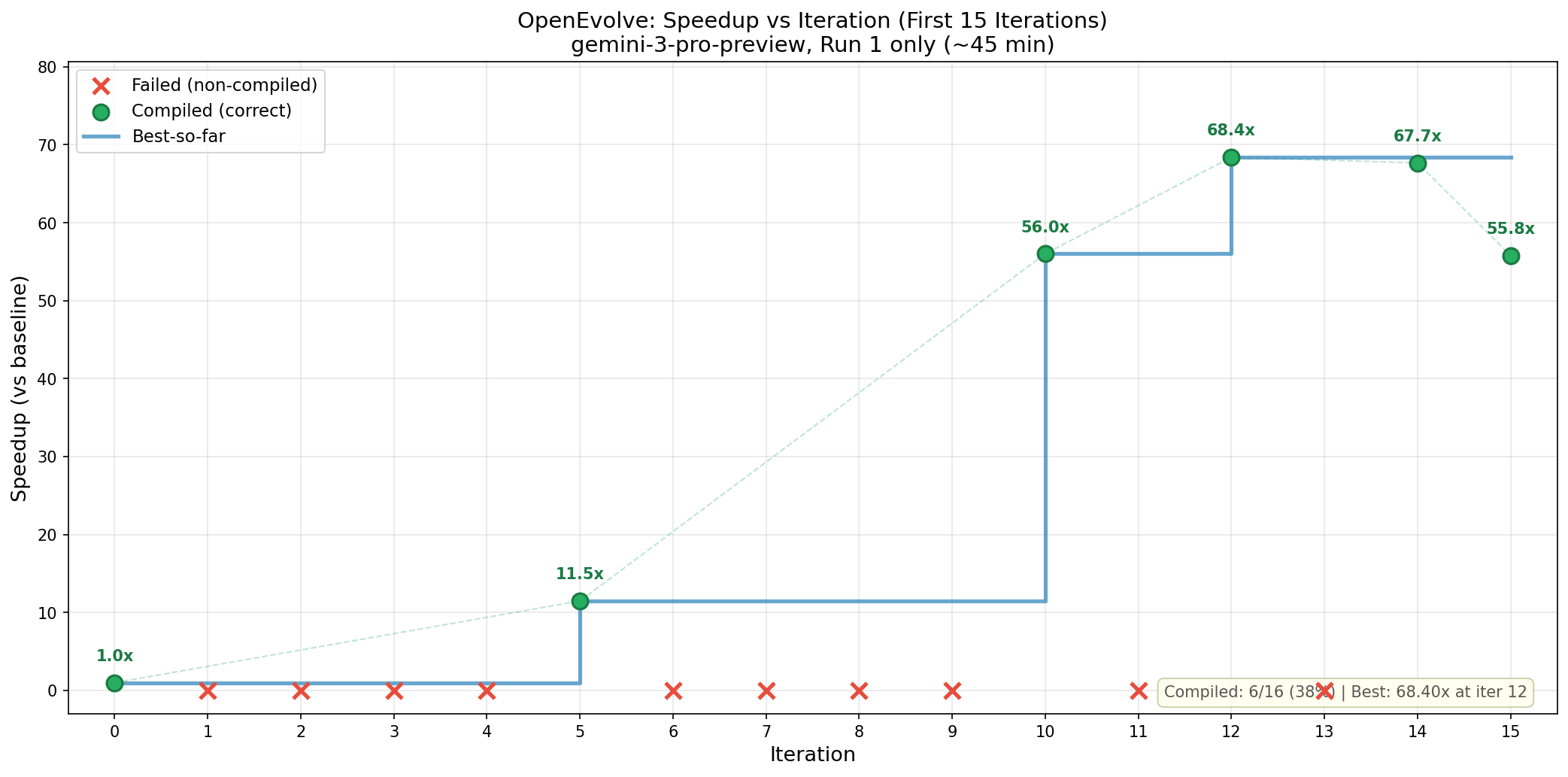
That was promising, so I ran it for 30 more iterations, but this barely improved the results - the best on is 2156 cycles.
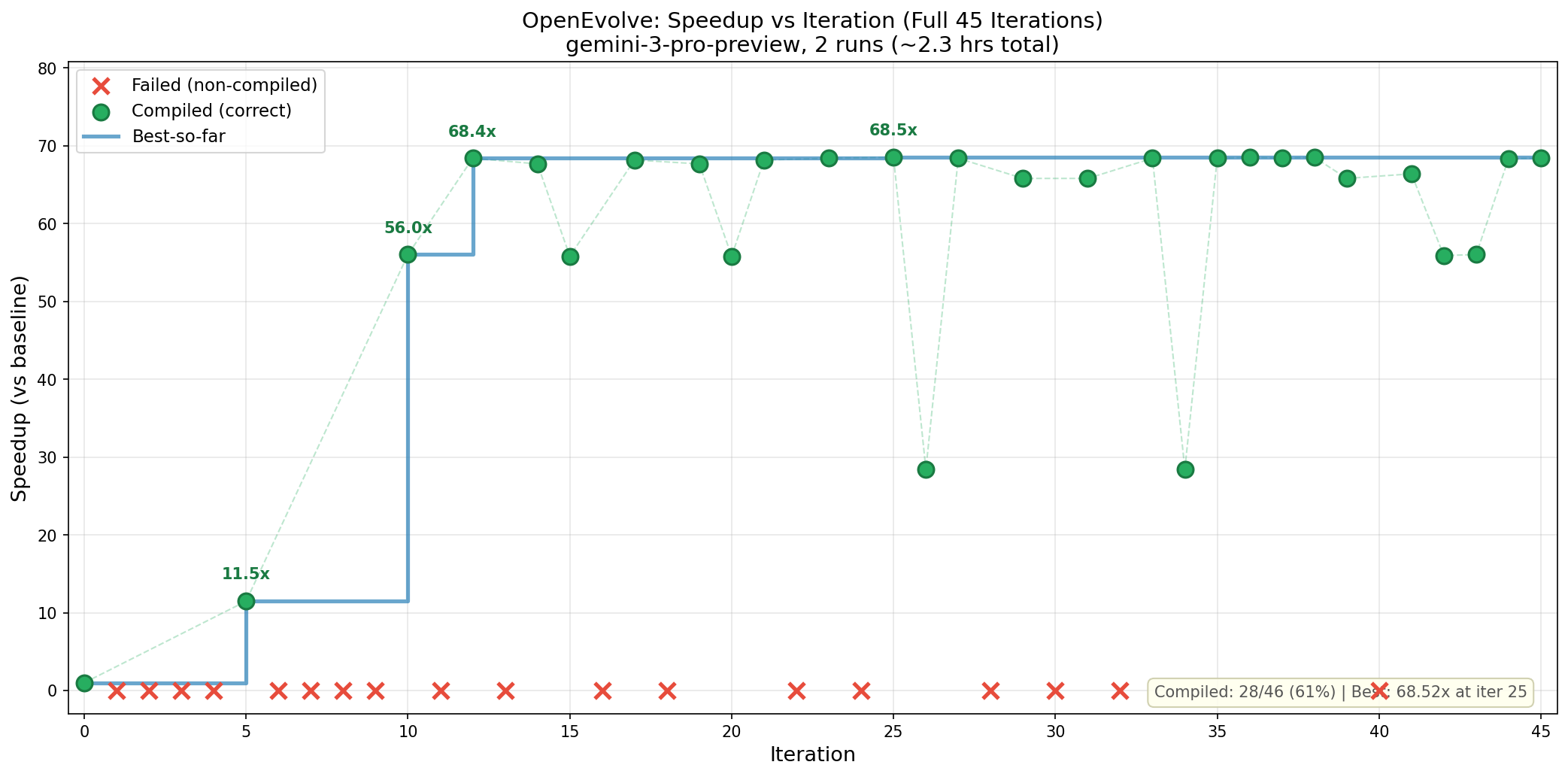
Here's a more detailed breakdown:
| Iter | Status | Speedup | Cycles | Time(s) |
|---|---|---|---|---|
| 0 | OK | 1.00x | 147734 | - |
| 1 | FAILED | - | - | 188.5 |
| 2 | FAILED | - | - | 201.7 |
| 3 | FAILED | - | - | 169.9 |
| 4 | FAILED | - | - | 186.0 |
| 5 | OK | 11.48x | 12865 | 160.7 |
| 6 | FAILED | - | - | 170.7 |
| 7 | FAILED | - | - | 147.7 |
| 8 | FAILED | - | - | 180.8 |
| 9 | FAILED | - | - | 159.8 |
| 10 | OK | 56.02x | 2637 | 161.1 |
| 11 | FAILED | - | - | 195.8 |
| 12 | OK | 68.40x | 2160 | 206.2 |
| 13 | FAILED | - | - | 137.1 |
| 14 | OK | 67.67x | 2183 | 193.2 |
| 15 | OK | 55.81x | 2647 | 208.9 |
| 16 | FAILED | - | - | 154.9 |
| 17 | OK | 68.17x | 2167 | 178.4 |
| 18 | FAILED | - | - | 186.2 |
| 19 | OK | 67.67x | 2183 | 214.7 |
| 20 | OK | 55.81x | 2647 | 174.2 |
| 21 | OK | 68.17x | 2167 | 224.3 |
| 22 | FAILED | - | - | 203.1 |
| 23 | OK | 68.40x | 2160 | 194.1 |
| 24 | FAILED | - | - | 214.1 |
| 25 | OK | 68.52x | 2156 | 211.0 |
| 26 | OK | 28.43x | 5196 | 191.3 |
| 27 | OK | 68.40x | 2160 | 172.8 |
| 28 | FAILED | - | - | 208.7 |
| 29 | OK | 65.81x | 2245 | 177.4 |
| 30 | FAILED | - | - | 151.7 |
| 31 | OK | 65.81x | 2245 | 151.6 |
| 32 | FAILED | - | - | 151.3 |
| 33 | OK | 68.40x | 2160 | 206.2 |
| 34 | OK | 28.43x | 5196 | 159.8 |
| 35 | OK | 68.40x | 2160 | 199.7 |
| 36 | OK | 68.52x | 2156 | 182.7 |
| 37 | OK | 68.43x | 2159 | 152.7 |
| 38 | OK | 68.52x | 2156 | 184.5 |
| 39 | OK | 65.81x | 2245 | 181.0 |
| 40 | FAILED | - | - | 176.7 |
| 41 | OK | 66.40x | 2225 | 188.4 |
| 42 | OK | 55.90x | 2643 | 163.4 |
| 43 | OK | 56.02x | 2637 | 197.4 |
| 44 | OK | 68.33x | 2162 | 204.3 |
| 45 | OK | 68.43x | 2159 | 147.7 |
About 1/3 of evolved programs crash, with the majority failing early in the evolution process. This underscores the importance of avoiding harsh filtering - even when the problem is complex enough that the LLM can't crack it initially, it's able to self-correct over time.
Conclusion
This is certainly not the best result achievable even with this simple setup. Some directions for future work:
- Stronger models - it would be interesting to see whether Claude Opus 4.5 in this setting could outperform an open-ended agent
- Higher temperature or model ensembles - more diversity to escape local optima
- Trace-guided feedback - the simulator can output Chrome Trace Format. Feeding pipeline stalls and utilization data back to the LLM could guide smarter optimizations1
- Optimizing the system prompt with research and optimization direction hints
I also tried other models, but neither performed well enough to make a meaningful multi-model comparison. OpenAI GPT-5.2 managed only a 3.84x speedup after 30 iterations, and Claude Sonnet 4.5 didn't improve beyond baseline within 20 iterations, at which point I was heavily rate-limited. All configs used the same setup - identical system prompt, temperature, and timeout - there's certainly room to tune per-model prompts and parameters, but that's a separate investigation. You're welcome to try it out and get better results!
This feels like the biggest limiting factor to me, though it applies to both evolutionary- and agent-style approaches↩